DB方式|DB設計|データ操作|トランザクション処理|DB応用
データベース方式
CAP定理におけるAとPの特性をもつ分散システムの説明として,適切なものはどれか。
- 可用性と整合性と分断耐性の全てを満たすことができる。
- 可用性と整合性を満たすが分断耐性を満たさない。
- 可用性と分断耐性を満たすが整合性を満たさない。
- 整合性と分断耐性を満たすが可用性を満たさない。
ANSI/SPARC3層スキーマモデルにおける内部スキーマの設計に含まれるのはどれか。
- SQL問合せ応答時間の向上を目的としたインデックスの定義
- エンティティ間の“1対多”,“多対多”などの関連を明示するE-Rモデルの作成
- エンティティ内やエンティティ間の整合性を保つための一意性制約や参照制約の設定
- データの冗長性を排除し,更新の一貫性と効率性を保持するための正規化
表に対するSQLのGRANT文の説明として,適切なものはどれか。
- パスワードを設定してデータベースへの接続を制限する。
- ビューを作成して,ビューの基となる表のアクセスできる行や列を制限する。
- 表のデータを暗号化して,第三者がアクセスしてもデータの内容が分からないようにする。
- 表の利用者に対し,表への問合せ,更新,追加,削除などの操作権限を付与する。
データベースを記録媒体にどのように格納するかを記述したものはどれか。
- 概念スキーマ
- 外部スキーマ
- サブスキーマ
- 内部スキーマ
データベース設計
データ項目の命名規約を設ける場合,次の命名規約だけでは回避できない事象はどれか。
〔命名規約〕
(1)データ項目名の末尾には必ず“名”,“コード”,“数”,“金額”,“年月日”などの区分語を付与し,区分語ごとに定めたデータ型にする。
(2)データ項目名と意味を登録した辞書を作成し,異音同義語や同音異義語が発生しないようにする。
- データ項目“受信年月日”のデータ型として,日付型と文字列型が混在する。
- データ項目“受注金額”の取り得る値の範囲がテーブルによって異なる。
- データ項目“賞与金額”と同じ意味で“ボーナス金額”というデータ項目がある。
- データ項目“取引先”が,“取引先コード”か“取引先名”か,判別できない。
第1,第2,第3正規形とそれらの特徴a~cの組合せとして,適切なものはどれか。
a:どの非キー属性も,主キーの真部分集合に対して関数従属しない。
b:どの非キー属性も,主キーに推移的に関数従属しない。
c:繰り返し属性が存在しない。
| 第1正規形 | 第2正規形 | 第3正規形 | |
| ア | a | b | c |
| イ | a | c | b |
| ウ | c | a | b |
| エ | c | b | a |
受注入力システムによって作成される次の表に関する記述のうち,適切なものはどれか。受注番号は受注ごとに新たに発行される番号であり,項番は1回の受注で商品コード別に連番で発行される番号である。なお,単価は商品コードによって一意に定まる。
| 受注日 | 受注番号 | 得意先コード | 項番 | 商品コード | 数量 | 単価 |
|---|---|---|---|---|---|---|
| 2021-03-05 | 995867 | 0256 | 1 | 20121 | 20 | 20,000 |
| 2021-03-05 | 995867 | 0256 | 2 | 24005 | 10 | 15,000 |
| 2021-03-05 | 995867 | 0256 | 3 | 28007 | 5 | 5,000 |
- 第1正規形でない。
- 第1正規形であるが第2正規形でない。
- 第2正規形であるが第3正規形でない。
- 第3正規形である。
商品の注文を記録するクラス(顧客,商品,注文,注文明細)の構造を概念データモデルで表現する。a〜dに入れるべきクラス名の組合せはどれか。ここで,顧客は何度も注文を行い,一度に一つ以上の商品を注文でき,注文明細はそれぞれ1種類の商品に対応している。また,モデルの表記にはUMLを用いる。

| a | b | c | d | |
| ア | 顧客 | 注文 | 注文明細 | 商品 |
| イ | 商品 | 注文 | 注文明細 | 顧客 |
| ウ | 注文 | 注文明細 | 顧客 | 商品 |
| エ | 注文明細 | 商品 | 注文 | 顧客 |
UMLを用いて表した図のデータモデルから,“部品”表,“納入”表及び“メーカ”表を関係データベース上に定義するときの解釈のうち,適切なものはどれか。
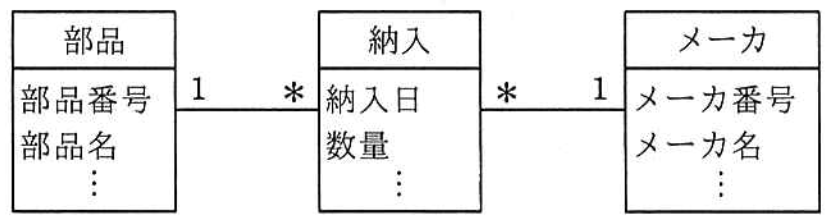
- 同一の部品を同一のメーカから複数回納入することは許されない。
- “納入”表に外部キーは必要ない。
- 部品番号とメーカ番号の組みを“納入”表の候補キーの一部にできる。
- “メーカ”表は,外部キーとして部品番号をもつことになる。
関係“注文記録”属性間①〜⑥の関数従属性があり,それに基づいて第3正規系まで正規化を行って“商品”,“顧客”,“注文”,“注文明細”の各関係に分解した。関係“注文明細”として,適切なものはどれか。ここで{X,Y}は,属性XとYの組みを表し,X → Yは,XがYに関数的に決定することを表す。また,実線の下線は主キーを表す。
注文記録(注文番号,注文日,顧客番号,顧客名,商品番号,商品名,数量,販売単価)
〔関数従属性〕
①注文番号 → 注文日
②注文番号 → 顧客番号
③顧客番号 → 顧客名
④{注文番号,商品番号} → 数量
⑤{注文番号,商品番号} → 販売単価
⑥商品番号 → 商品名
- 注文明細(注文番号,顧客番号,商品番号,顧客名,数量,販売単価)
- 注文明細(注文番号,顧客番号,数量,販売単価)
- 注文明細(注文番号,商品番号,数量,販売単価)
- 注文明細(注文番号,数量,販売単価)
データベースの概念設計に用いられ,対象世界を,実体と実体間の関連という二つの概念で表現するデータモデルはどれか。
- E-Rモデル
- 階層モデル
- 関係モデル
- ネットワークモデル
社員と年の対応関係をUMLのクラス図で記述する。二つのクラス間の関連が次の条件を満たす場合,a,bに入れる多重度の適切な組合せはどれか。ここで,“年”クラスのインスタンスは毎年存在する。
〔条件〕
(1)全ての社員は入社年を特定できる。
(2)年によっては社員が入社しないこともある。

| a | b | |
| ア | 0..* | 0..1 |
| イ | 0..* | 1 |
| ウ | 1..* | 0..1 |
| エ | 1..* | 1 |
自然数を除数とした剰余を返すハッシュ関数がある。値がそれぞれ571,1168,1566である三つのレコードのキー値を入力値としてこのハッシュ関数を施したところ,全てのハッシュ値が衝突した。このとき使用した除数は幾つか。
- 193
- 197
- 199
- 211
第3正規形であることの効果又は影響に関する記述として,適切なものはどれか。
- 画面や帳票の行をそのままデータベースの行に対応させるので,データ量が増える。
- 結合操作が不要となり,データベース全体の処理効率が向上する。
- 更新時のデッドロックを避けることができる。
- 冗長性が排除され,データの整合性を保ちやすくなる。
データモデルを解釈してオブジェクト図を作成した。解釈の誤りを適切に指摘した記述はどれか。ここで,モデルの表記にはUMLを用い,オブジェクト図の一部の属性の表示は省略した。

- “123456:注文”が複数の商品にリンクしているのは,誤りである。
- “2ドア冷蔵庫:商品”が複数の注文にリンクしているのは,誤りである。
- “A商店:顧客”が複数の注文にリンクしているのは,誤りである。
- “ドラム式洗濯機:商品”がどの注文にもリンクしていないのは,誤りである。
“受注明細”表は,どのレベルまでの正規形の条件を満足しているか。ここで,実線の下線は主キーを表す。
| 受注番号 | 明細番号 | 商品コード | 商品名 | 数量 |
|---|---|---|---|---|
| 015867 | 1 | TV20006 | 20型TV | 20 |
| 015867 | 2 | TV24005 | 24型TV | 10 |
| 015867 | 3 | TV28007 | 28型TV | 5 |
| 015868 | 1 | TV24005 | 24型TV | 8 |
- 第1正規形
- 第2正規形
- 第3正規形
- 第4正規形
データ操作
“従業員”表に対して“異動”表による差集合演算を行った結果はどれか。
| 従業員ID | 従業員名 | 所属 |
|---|---|---|
| A001 | 情報太郎 | 人事部 |
| A005 | 情報花子 | 経理部 |
| B010 | 情報次郎 | 総務部 |
| C003 | 試験桃子 | 人事部 |
| C011 | 試験一郎 | 経理部 |
| 従業員ID | 従業員名 | 所属 |
|---|---|---|
| A005 | 情報花子 | 経理部 |
| B010 | 情報次郎 | 総務部 |
| D080 | 技術桜子 | 経理部 |
-
従業員ID 従業員名 所属 A001 情報太郎 人事部 A005 情報花子 経理部 B010 情報次郎 総務部 C003 試験桃子 人事部 C011 試験一郎 経理部 D080 技術桜子 経理部 -
従業員ID 従業員名 所属 A001 情報太郎 人事部 C003 試験桃子 人事部 C011 試験一郎 経理部 -
従業員ID 従業員名 所属 A005 情報花子 経理部 B010 情報次郎 総務部 -
従業員ID 従業員名 所属 D080 技術桜子 経理部
“商品”表に対して,次のSQL文を実行して得られる仕入先コード数は幾つか。
〔SQL文〕
SELECT DISTINCT 仕入先コード FROM 商品
WHERE(販売単価 - 仕入単価) >
(SELECT AVG(販売単価 - 仕入単価) FROM 商品)
| 商品コード | 商品名 | 販売単価 | 仕入先コード | 仕入単価 |
|---|---|---|---|---|
| A001 | A | 1,000 | S1 | 800 |
| B002 | B | 2,500 | S2 | 2,300 |
| C003 | C | 1,500 | S2 | 1,400 |
| D004 | D | 2,500 | S1 | 1,600 |
| E005 | E | 2,000 | S1 | 1,600 |
| F006 | F | 3,000 | S3 | 2,800 |
| G007 | G | 2,500 | S3 | 2,200 |
| H008 | H | 2,500 | S4 | 2,000 |
| I009 | I | 2,500 | S5 | 2,000 |
| J010 | J | 1,300 | S6 | 1,000 |
- 1
- 2
- 3
- 4
関係Rと関係Sに対して,関係Xを求める関係演算はどれか。

- IDで結合
- 差
- 直積
- 和
“部門別売上”表から,部門コードごと,期ごとの売上を得るSQL文はどれか。

- SELECT 部門コード, '第1期' AS 期, 第1期売上 AS 売上
FROM 部門別売上
INTERSECT
(SELECT 部門コード, '第2期' AS 期, 第2期売上 AS 売上
FROM 部門別売上) ORDER BY 部門コード, 期 - SELECT 部門コード, '第1期' AS 期, 第1期売上 AS 売上
FROM 部門別売上
UNION
(SELECT 部門コード, '第2期' AS 期, 第2期売上 AS 売上
FROM 部門別売上) ORDER BY 部門コード, 期 - SELECT A.部門コード, '第1期' AS 期, A.第1期売上 AS 売上
FROM 部門別売上 A
CROSS JOIN
(SELECT B.部門コード, '第2期' AS 期, B.第2期売上 AS 売上
FROM 部門別売上) T ORDER BY 部門コード, 期 - SELECT A.部門コード, '第1期' AS 期, A.第1期売上 AS 売上
FROM 部門別売上
INNER JOIN
(SELECT B.部門コード, '第2期' AS 期, B.第2期売上 AS 売上
FROM 部門別売上) T ON A.部門コード = T.部門コード ORDER BY 部門コード, 期
“東京在庫”表と“大阪在庫”表に対して,SQL文を実行して得られる結果はどれか。ここで,実線の下線は主キーを表す。

〔SQL文〕
SELECT 商品コード, 在庫数 FROM 東京在庫
UNION ALL
SELECT 商品コード, 在庫数 FROM 大阪在庫

図のような関係データベースの“注文”表と“注文明細”表がある。“注文”表の行を削除すると,対応する“注文明細”表の行が,自動的に削除されるようにしたい。SQL文のON DELETE句に指定する語句はどれか。ここで,図中の実線の下線は主キーを,破線の下線は外部キーを表す。

- CASCADE
- INTERSECT
- RESTRICT
- UNIQUE
RDBMSにおいて,特定の利用者だけに表を更新する権限を与える方法として,適切なものはどれか。
- CONNECT文で接続を許可する。
- CREATE ASSERTION文で表明して制限する。
- CREATE TABLE文の参照制約で制限する。
- GRANT文で許可する。
過去3年分の記録を保存している“試験結果”表から,2018年度の平均点数が600点以上となったクラスのクラス名と平均点数の一覧を取得するSQL文はどれか。ここで,実線の下線は主キーを表す。
試験結果(学生番号,受験年月日,点数,クラス名)
- SELECT クラス名, AVG(点数) FROM 試験結果
GROUP BY クラス名 HAVING AVG(点数) >= 600 - SELECT クラス名, AVG(点数) FROM 試験結果
WHERE 受験年月日 BETWEEN '2018-04-01' AND '2019-03-31'
GROUP BY クラス名 HAVING AVG(点数) >= 600 - SELECT クラス名, AVG(点数) FROM 試験結果
WHERE 受験年月日 BETWEEN '2018-04-01' AND '2019-03-31'
GROUP BY クラス名 HAVING 点数 >= 600 - SELECT クラス名, AVG(点数) FROM 試験結果
WHERE 点数 >= 600
GROUP BY クラス名
HAVING (MAX(受験年月日)
BETWEEN '2018-04-01' AND '2019-03-31')
ストアドプロシージャの利点はどれか。
- アプリケーションプログラムからネットワークを介してDBMSにアクセスする場合,両者間の通信量を減少させる。
- アプリケーションプログラムからの一連の要求を一括して処理することによって,DBMS内の実行計画の数を減少させる。
- アプリケーションプログラムからの一連の要求を一括して処理することによって,DBMS内の必要バッファ数を減少させる。
- データが格納されているディスク装置へのI/O回数を減少させる。
関係R(ID,A,B,C)のA,Cへの射影の結果とSQL文で求めた結果が同じになるように,aに入れるべき字句はどれか。ここで,関係Rを表Tで実現し,表Tに各行を格納したものを次に示す。

- ALL
- DISTINCT
- ORDER BY
- REFERENCES
トランザクション処理
チェックポイントを取得するDBMSにおいて,図のような時間経過でシステム障害が発生した。前進復帰(ロールフォワード)によって障害回復できるトランザクションだけを全て挙げたものはどれか。

- T1
- T2とT3
- T4とT5
- T5
ACID特性の四つの性質に含まれないものはどれか。
- 一貫性
- 可用性
- 原子性
- 耐久性
undo/redo方式を用いた障害回復におけるログ情報の要否として,適切な組合せはどれか。
| 更新前情報 | 更新後情報 | |
| ア | 必要 | 必要 |
| イ | 必要 | 不要 |
| ウ | 不要 | 必要 |
| エ | 不要 | 不要 |
データベースの障害回復処理に関する記述として,適切なものはどれか。
- 異なるトランザクション処理プログラムが,同一データベースを同時更新することによって生じる論理的な矛盾を防ぐために,データのブロック化が必要となる。
- システムが媒体障害以外のハードウェア障害によって停止した場合,チェックポイントの取得以前に終了したトランザクションについての回復作業は不要である。
- データベースの媒体障害に対して,バックアップファイルをリストアした後,ログファイルの更新前情報を使用してデータの回復処理を行う。
- トランザクション処理プログラムがデータベースの更新中に異常終了した場合には,ログファイルの更新後情報を使用してデータの回復処理を行う。
コストベースのオプティマイザがSQLの実行計画を作成する際に必要なものはどれか。
- ディメンジョンテーブル
- 統計情報
- 待ちグラフ
- ログファイル
トランザクションのACID特性のうち,耐久性(durability)に関する記述として,適切なものはどれか。
- 正常に終了したトランザクションの更新結果は,障害が発生してもデータベースから消失しないこと
- データベースの内容が矛盾のない状態であること
- トランザクションの処理が全て実行されるか,全く実行されないかのいずれかで終了すること
- 複数のトランザクションを同時に実行した場合と,順番に実行した場合の処理結果が一致すること
RDBMSのロックに関する記述のうち,適切なものはどれか。ここで,X,Yはトランザクションとする。
- XがA表内の特定行aに対して共有ロックを獲得しているときは,YはA表内の別の特定行bに対して専有ロックを獲得することができない。
- XがA表内の特定行aに対して共有ロックを獲得しているときは,YはA表に対して専有ロックを獲得することができない。
- XがA表に対して共有ロックを獲得しているときでも,YはA表に対して専有ロックを獲得することができる。
- XがA表に対して専有ロックを獲得しているときでも,YはA表内の特定行aに対して専有ロックを獲得することができる。
データベースに媒体障害が発生したときのデータベースの回復法はどれか。
- 障害発生時,異常終了したトランザクションをロールバックする。
- 障害発生時点でコミットしていたがデータベースの実更新がされていないトランザクションをロールフォワードする。
- 障害発生時点でまだコミットもアボートもしていなかった全てのトランザクションをロールバックする。
- バックアップコピーでデータベースを復元し,バックアップ取得以降にコミットした全てのトランザクションをロールフォワードする。
分散トランザクション管理において,複数サイトのデータベースを更新する場合に用いられる2相コミットプロトコルに関する記述のうち,適切なものはどれか。
- 主サイトが一部の従サイトからのコミット準備完了メッセージを受け取っていない場合,コミット準備が完了した従サイトに対してだけコミット要求を発行する。
- 主サイトが一部の従サイトからのコミット準備完了メッセージを受け取っていない場合,全ての従サイトに対して再度コミット準備要求を発行する。
- 主サイトが全ての従サイトからコミット準備完了メッセージを受け取った場合,全ての従サイトに対してコミット要求を発行する。
- 主サイトが全ての従サイトに対してコミット準備要求を発行した場合,従サイトは,コミット準備が完了したときだけ応答メッセージを返す。
トランザクションのACID特性のうち,一貫性(consistency)の記述として,適切なものはどれか。
- 整合性の取れたデータベースに対して,トランザクション実行後も整合性が取れている性質である。
- 同時実行される複数のトランザクションは互いに干渉しないという性質である。
- トランザクションは,完全に実行が完了するか,全く実行されなかったかの状態しかとらない性質である。
- ひとたびコミットすれば,その後どのような障害が起こっても状態の変更が保たれるという性質である。
“部品”表のメーカコード列に対し,B+木インデックスを作成した。これによって,“部品”表の検索の性能改善が最も期待できる操作はどれか。ここで,部品及びメーカのデータ件数は十分に多く,“部品”表に存在するメーカコード列の値の種類は十分な数があり,かつ,均一に分散されているものとする。また,“部品”表のごく少数の行には,メーカコード列にNULLが設定されている。実線の下線は主キーを,破線の下線は外部キーを表す。
- メーカコードの値が1001以外の部品を検索する。
- メーカコードの値が1001でも4001でもない部品を検索する。
- メーカコードの値が4001以上,4003以下の部品を検索する。
- メーカコードの値がNULL以外の部品を検索する。
データベースシステムにおいて,二つのプログラムが同一データへのアクセス要求を行うとき,後続プログラムのアクセス要求に対する並行実行の可否の組合せのうち,適切なものはどれか。ここで,表中の○は二つのプログラムが並行して実行されることを表し,×は先行プログラムの実行終了まで後続プログラムは待たされることを表す。

関係データベースのテーブルにレコードを1件追加したところ,インデックスとして使う,図のB+木のリーフノードCがノードC1とC2に分割された。ノード分割後のB+木構造はどれか。ここで,矢印はノードへのポインタとする。また,中間ノードAには十分な空きがあるものとする。

SQLにおいて,A表の主キーがB表の外部キーによって参照されている場合,各表の行を追加・削除する操作の参照制約について,正しく整理した図はどれか。ここで,△印は操作が拒否される場合があることを表し,○印は制限なしに操作ができることを表す。

トランザクションA~Gの待ちグラフにおいて,永久待ちの状態になっているトランザクション全てを列挙したものはどれか。ここで,待ちグラフのX→Yは,トランザクションXはトランザクションYがロックしている資源のアンロックを待っていることを表す。

- A,B,C,D
- B,C,D
- B,C,D,F
- C,D,E,F,G
トランザクションAとBが,共通の資源であるテーブルaとbを表に示すように更新するとき,デッドロックとなるのはどの時点か。ここで,表中の①~⑧は処理の実行順序を示す。また,ロックはテーブルの更新直前にテーブル単位で行い,アンロックはトランザクションの終了後に行うものとする。

- ③
- ④
- ⑤
- ⑥
データベース応用
ビッグデータの利用におけるデータマイニングを説明したものはどれか。
- 蓄積されたデータを分析し,単なる検索だけでは分からない隠れた規則や相関関係を見つけ出すこと
- データウェアハウスに格納されたデータの一部を,特定の用途や部門用に切り出して,データベースに格納すること
- データ処理の対象となる情報を基に規定した,データの構造,意味及び操作の枠組みのこと
- データを複数のサーバに複製し,性能と可用性を向上させること
分散データベースにおける“複製に対する透過性”の説明として,適切なものはどれか。
- それぞれのサーバのDBMSが異種であっても,プログラムはDBMSの相違を意識する必要がない。
- 一つの表が複数のサーバに分割されて配置されていても,プログラムは分割された配置を意識する必要がない。
- 表が別のサーバに移動されても,プログラムは表が配置されたサーバを意識する必要がない。
- 複数のサーバに一つの表が重複して存在しても,プログラムは表の重複を意識する必要がない。
NoSQLの一種である,グラフ指向DBの特徴として,適切なものはどれか。
- データ項目の値として階層構造のデータをドキュメントとしてもつことができる。また,ドキュメントに対しインデックスを作成することもできる。
- ノード,リレーション,プロパティで構成され,ノード間をリレーションでつないで構造化する。ノード及びリレーションはプロパティをもつことができる。
- 一つのキーに対して一つの値をとる形をしている。値の型は定義されていないので,様々な型の値を格納することができる。
- 一つのキーに対して複数の列をとる形をしている。関係データベースとは異なり,列の型は固定されていない。
データレイクの特徴はどれか。
- 大量のデータを分析し,単なる検索だけでは分からない隠れた規則や相関関係を見つけ出す。
- データウェアハウスに格納されたデータから特定の用途に必要なデータだけを取り出し,構築する。
- データウェアハウスやデータマートからデータを取り出し,多次元分析を行う。
- 必要に応じて加工するために,データを発生したままの形で格納する。
ビッグデータのデータ貯蔵場所であるデータレイクの特徴として,適切なものはどれか。
- あらゆるデータをそのままの形式や構造で格納しておく。
- データ量を抑えるために,データの記述情報であるメタデータは格納しない。
- データを格納する前にデータ利用方法を設計し,それに沿ってスキーマをあらかじめ定義しておく。
- テキストファイルやバイナリデータなど,格納するデータの形式に応じてリポジトリを使い分ける。
関係データベース管理システム(RDBMS)のデータディクショナリに格納されるものはどれか。
- OSが管理するファイルの定義情報
- スキーマの定義情報
- 表に格納された列データの組
- 表の列に付けられたインデックスの内容
ビッグデータの基盤技術として利用されるNoSQLに分類されるデータベースはどれか。
- 関係データモデルをオブジェクト指向データモデルに拡張し,操作の定義や型の継承関係の定義を可能としたデータベース
- 経営者の意思決定を支援するために,ある主題に基づくデータを現在の情報とともに過去の情報も蓄積したデータベース
- 様々な形式のデータを一つのキーに対応付けて管理するキーバリュー型データベース
- データ項目の名称や形式など,データそのものの特性を表すメタ情報を管理するデータベース
データマイニングの説明として,適切なものはどれか。
- 基幹業務のデータベースとは別に作成され,更新処理をしない集計データの分析を主目的とする。
- 個人別データ,部門別データ,サマリデータなど,分析の目的別に切り出され,カスタマイズされたデータを分析する。
- スライシング,ダイシング,ドリルダウンなどのインタラクティブな操作によって多次元分析を行い,意思決定を支援する。
- ニューラルネットワークや統計解析などの手法を使って,大量に蓄積されているデータから,特徴あるパターンを探し出す。